Deploying ResNet50 semantic segmentation model on the nVidia Jetson Nano using onnxruntime
When we upgraded our robot Beteigeuze with entirely new electronic components, we decided on nVidia’s Jetson Nano platform as the robot’s primary computer. The Jetson Nano is an ARM based quad-core System-on-a-Chip (SOC) that features CUDA acceleration for Deep Learning models.
As a test, we tried deploying the model that we used during last year’s Virtual Field Robot Event on the new hardware platform. Even though that model was trained for simulation, we hope that models of the same or similar architecture will be of value for us in this year’s event. The model is a ResNet50 from PyTorch’s torchvision.
For inference, we exported the trained model to the ONNX format for easy deployment and portability. ONNX allows for saving the model and its weights in a single file, that can then be loaded an used using the ONNX Runtime, which is available for a wide range of platforms.
For last year’s event, we just used the CPU version of onnxruntime. While no GPU was available on the competition server, that machine’s CPU was sufficient for running the model alongside all the other code, and performance was less critical due to the simulation running slower than real time anyway. On the real robot, constraints are different: CPU time on the Jetson Nano is valuable, and therefore it make sense to utilize the available CUDA cores for the image recognition pipeline.
Since Ubuntu 18.04 is the only supported operating system on the Jetson Nano platform (please tell us if you know of an equivalent platform not stuck to badly aging proprietary drivers!), building ONNX runtime was not entirely straightforward. For this reason, we document the process here. We assume that JetPack 4.6 is already installed. So our /etc/apt/sources.list.d/nvidia-l4t-apt-source.list contains these entries.
deb https://repo.download.nvidia.com/jetson/common r32.6 main
deb https://repo.download.nvidia.com/jetson/t210 r32.6 mainFor a more elaborate guide on how to install JetPack, see the official guide.
Next, we had to install a current version of CMake:
echo 'export PATH=$HOME/.local/bin:$PATH' >> ~/.bashrc
source ~/.bashrc
cd ~/Downloads
wget https://github.com/Kitware/CMake/releases/download/v3.22.2/cmake-3.22.2.tar.gz
mkdir -p ~/cmake && cd ~/cmake
tar xf ~/Downloads/cmake-3.22.2.tar.gz
cd cmake-3.22.2/
./bootstrap --prefix=/home/beteigeuze/.local
make -j4
make installNext, we needed to build and install the ONNX Runtime with appropriate GPU support
cd ~
git clone https://github.com/microsoft/onnxruntime/
cd onnxruntime
git checkout v1.10.0
export CUDACXX=/usr/local/cuda-10.2/bin/nvcc
./build.sh --update --parallel --config Release --build --build_wheel --use_cuda --cuda_home /usr/local/cuda --cudnn_home /usr/lib/aarch64-linux-gnuThe resulting Python package could then be installed using:
pip3 install --user ./build/Linux/Release/dist/onnxruntime_gpu-1.10.0-cp36-cp36m-linux_aarch64.whlWe were then able to run the inference on the GPU using the Jupyter Notebook we provided when releasing our model and dataset last year (see the repository’s README for usage information and download link for the models’s ONNX file). However, LD_LIBRARY_PATH needs to be modified due to an obscure bug that a helpful person on Github has fortunately found a workaround for, and OPENBLAS_CORETYPE needs to be set as well:
export LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libgomp.so.1
export OPENBLAS_CORETYPE=CORTEXA57
jupyter-notebook 2-Inference.ipynb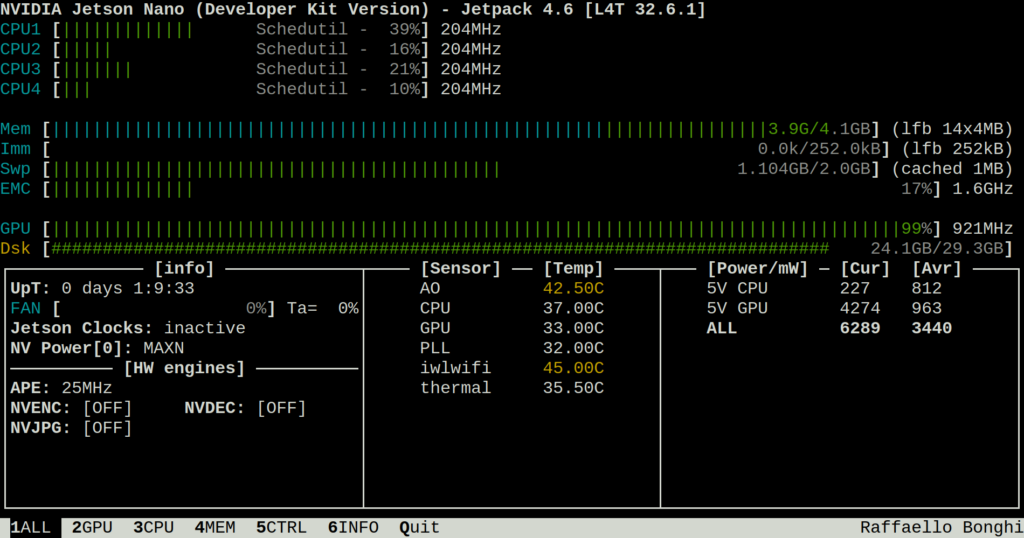
Inference takes about 2.1 seconds per image, which might be too slow for the competition. However, this is the original model that we used during the Virtual Field Robot Event, where performance was less of a concern, so there is likely room for optimization.
Keine Kommentare